In December 2024, we conducted a comprehensive analysis of AI crawler behavior by processing millions of server requests across various high-traffic websites. Our findings fundamentally challenge conventional wisdom about web analytics and content optimization for AI systems. Here's our deep dive into the methodology, findings, and implications for web architecture.
The traditional analytics blind spot
Traditional web analytics tools were built for human visitors who execute JavaScript, maintain cookies, and follow predictable browsing patterns. However, as AI systems become primary channels for content discovery and interpretation, these tools are missing a crucial part of web traffic.
The fundamental mismatch occurs because traditional analytics expects visitors to:
- Execute client-side JavaScript
- Maintain session state
- Follow predictable user flows
- Generate trackable events
Our methodology: server-side analysis
Instead of relying on client-side tracking, we analyzed raw server logs from multiple high-traffic websites. This server-side approach revealed traffic patterns that would have been invisible to traditional analytics tools. By processing billions of requests through our detection engine, we were able to identify and classify different types of AI crawlers with high accuracy.
Key findings from December 2024
Our analysis revealed several striking patterns:
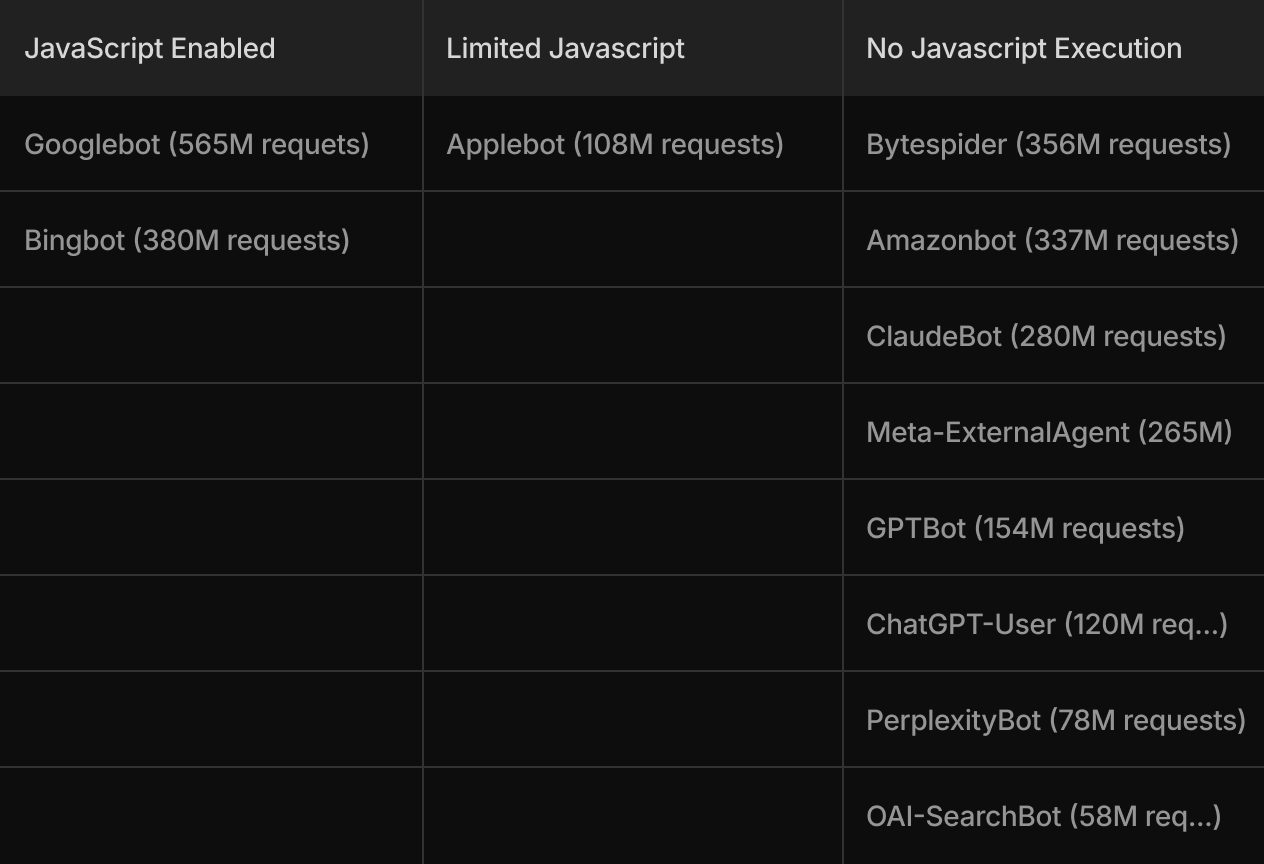
1. The JavaScript execution divide
Our data shows a clear divide in JavaScript handling capabilities:
2. The RAG pipeline reality
Understanding how content flows into AI systems revealed a complex pipeline:
- Foundation Layer: Traditional Search Indexes
- AI systems heavily rely on Google and Bing indexes for initial content discovery
- JavaScript-rendered content can still be discovered through these traditional indexes
- However, emerging AI search providers like Meta do not have JavaScript rendering capabilities for indexing
- This creates a compound effect: content requiring JavaScript rendering might be invisible to both the foundation layer AND real-time crawling
- Real-time Layer: Direct AI Crawling
- AI systems perform additional crawling for fresh content
- These crawlers don't execute JavaScript
- Creates a potential gap between indexed content and real-time updates
- Retrieval Layer: Content Selection
- AI systems combine both indexed and fresh content
- Content accessibility in raw HTML becomes crucial for real-time updates
Technical implications
These findings have significant implications for web architecture:
- Content Delivery
- Server-side rendering (SSR) becomes crucial for AI visibility
- Static HTML export paths may be necessary for dynamic content
- Initial HTML response should contain critical content
- JavaScript Dependencies
- Core content should not rely on JavaScript for rendering
- Progressive enhancement becomes more important
- Client-side routing needs server-side fallbacks
- Analytics Implementation
- Client-side only analytics miss significant AI traffic
- Server-side logging becomes crucial for complete visibility
- Bot detection needs to account for varying crawler behaviors
Introducing Profound Agent Analytics
Based on these findings, we developed Profound Agent Analytics to provide comprehensive visibility into AI system interactions. Our platform integrates directly with server logs to:
- Identify and Classify
- Accurate bot detection and classification
- Traffic pattern analysis
- Crawler behavior monitoring
- Monitor and Track
- Real-time crawler activity
- Content access patterns
- Response time analytics
- Optimize and Improve
- Content accessibility scoring
- Cache effectiveness monitoring
- Performance optimization recommendations
Looking forward
As AI systems continue to evolve, we expect to see:
- More sophisticated crawling behaviors
- Better JavaScript handling capabilities
- New patterns in content selection and citation
However, the core principle remains: understanding how AI systems consume your content is crucial for optimization. Web architects and developers need to:
- Implement robust server-side rendering
- Ensure critical content is available in initial HTML
- Monitor AI crawler interactions through server-side analytics
- Maintain balance between traditional search and AI optimization
The shift to AI-first content discovery requires new tools and approaches. By understanding how AI systems actually consume web content, we can better optimize for this new paradigm.
Want to learn more about how AI systems interact with your website? Get started with Profound Agent Analytics for comprehensive AI visibility.